【领域】视频 UGC 领域思考和归纳
工欲善其事,必先利其器。
为了更合理高效的迭代产品,自认为需要全面深入的认知所负责领域。
以下是阶段性的思考,会持续更新和丰富。
领域角色
- 内容消费用户(普通/会员)
- 内容创作用户(创作者)
- 内容治理用户(运营/开发者/产品策划)
各角色关系领域简图(初版) ↓
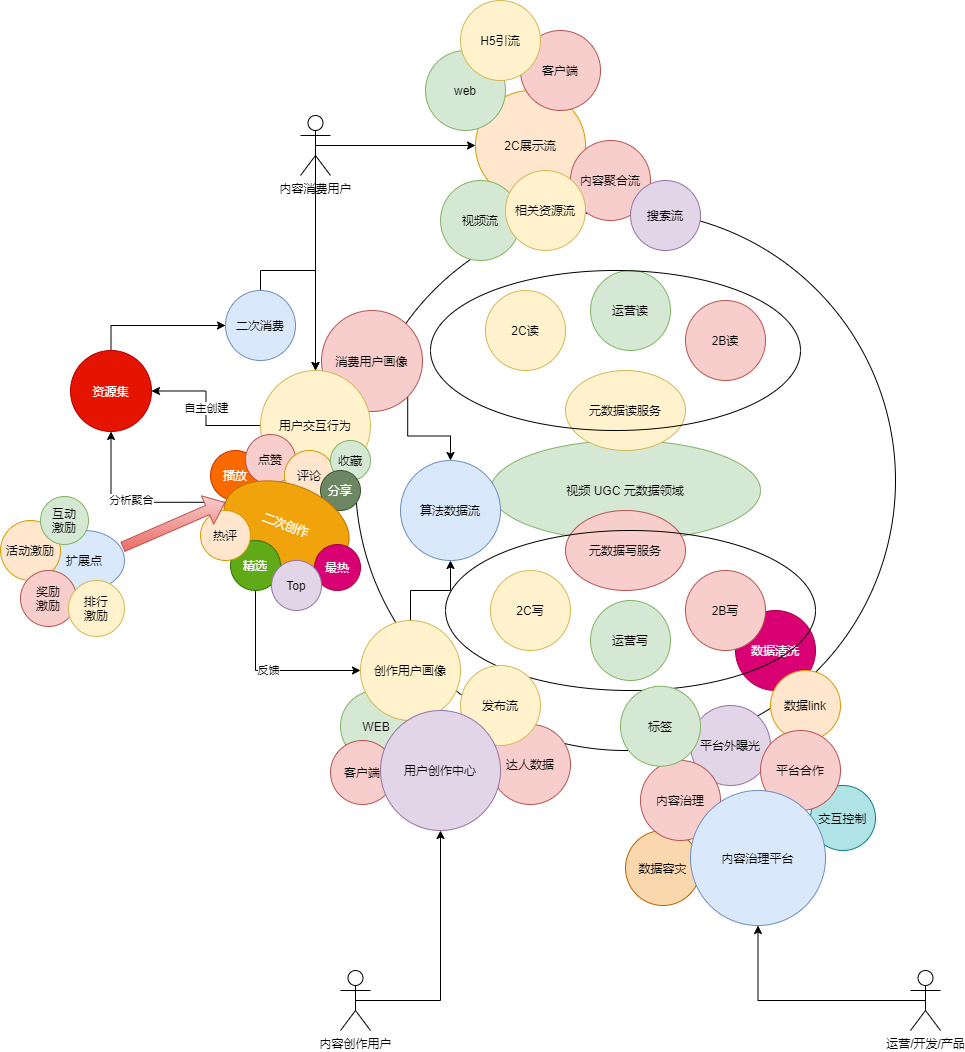
内容消费用户行为领域
内容消费用户特征
- 用户离散(种类繁多)
- 粘性相对小(其他角色有工作性质)
- 占比极高(相较其他角色)
内容消费用户基础行为
- 打开(用户粘性)
- 浏览(用户粘性)
- 播放(用户粘性+)
- 滑动浏览/播放(用户粘性++)
- 搜索(用户粘性+++)
- 关闭(用户粘性-)
1、基础行为是体验的基石,界面要避免复杂化。
2、基础行为模式不要频繁变化,促进用户养成习惯粘性。
内容消费用户交互行为(二次生产)
- 点赞(偏好)
- 评论(偏好+/二次创作)
- 转发/分享(偏好++/二次曝光)
- 收藏(偏好+++)
- 创建/添加到资源集(二次创作)
- 不感兴趣(偏好-)
1、交互行为是平台生命力的体现,交互越简单、越频繁,内容越丰富。
2、交互行为能产生大量二次创作,而促进普通用户二次创作是增强社区活力的重要手段,其流量大、内容广、产量高。
内容消费用户互动行为
- 添加好友/关注用户(互动粘性+)
- @ 其他用户(互动粘性++)
- 评论/回复(二次生产+互动粘性++)
- 私信(互动粘性++)
- 软件其他个性互动功能(个性化+/产品营销++)
1、互动行为是用户增长的重要渠道,好的互动能极大加深产品和用户的羁绊。
2、互动记录是很重要的情节纽带信息,最好要能让用户密切回溯和关注。
内容创作用户行为领域
创作用户分类和意图分析
- 普通用户生产内容(分享/交流/认同诉求)–> 离散生产/优质占比低/体量大
- 专业用户生产内容(流量/扩大影响力/品牌塑造/收益)–> 优质生产/品类明确
- 职业用户生产内容(收益/职业扩展)–> 优质占比高/生产频率保证
- MCN 机构用户生产内容(网红孵化/流量/收益)–> 量产/自主营销引流/质量保障
1、相信所有用户都有创作能力,开放创作入口和简化创作步骤,引导产生更多有效内容(初期加大力度)。
2、重视和运营优质创作者,提高社区内容质量,走可持续发展(前中后期)。
创作用户和角色例举
- 普通用户:游客、账号用户、VIP 用户
- 专业用户:名人、大 V、音乐人
- 职业用户:Up 主、达人、专栏作家
- 机构用户:机构下的子用户、机构下的网红
专业/职业/机构等内容创作用户特征
- 占比小(相较消费用户)
- 目标性强(定向输出)
- 与平台存在利益关系
- 主动(发布作品)+ 被动(点赞/评论/私信 互动)粘性
职业内容创作用户基础行为
- 入驻(重要渠道,可调整门槛)
- 发布作品(生产创作核心)
- 修改作品(弱操作)
- 删除作品(弱操作)
- 查看作品数据(播放/赞/评论/分享/收藏,强操作)
- 查看收益(重要数据)
- 提现(重要体验)
内容治理用户行为领域
内容治理用户泛化
- 运营(数据治理)
- 开发(功能/性能治理)
- 策划(体验治理)
1、内容治理用户不仅仅是运营,还有隐藏在后方的开发和产品。
2、内容治理不仅仅是数据治理,还有数据相关的页面交互和性能稳定。
内容治理范畴
- 内容数据治理(机审、人审、打标签、规则匹配、聚合产出、数据分析等)
- 内容交互治理(展示样式、投放控制、生产引导、曝光入口、互动流程、行为埋点分析等)
- 内容性能治理(T+1 -> 即时、搜索索引、增量聚合、容灾兜底、静态化、降级、限流等)
1、内容治理基本涉及一个 APP 的所有功能或相关扩展点,它是一个综合管理范畴。
2、初期的内容治理功能弱且仅考虑给运营用,然所有开发和交互相关的范式都可以扩展到内容治理,供所有治理角色使用。
3、扩展和丰富内容治理功能是后期提高生产力的一个重要发力点。
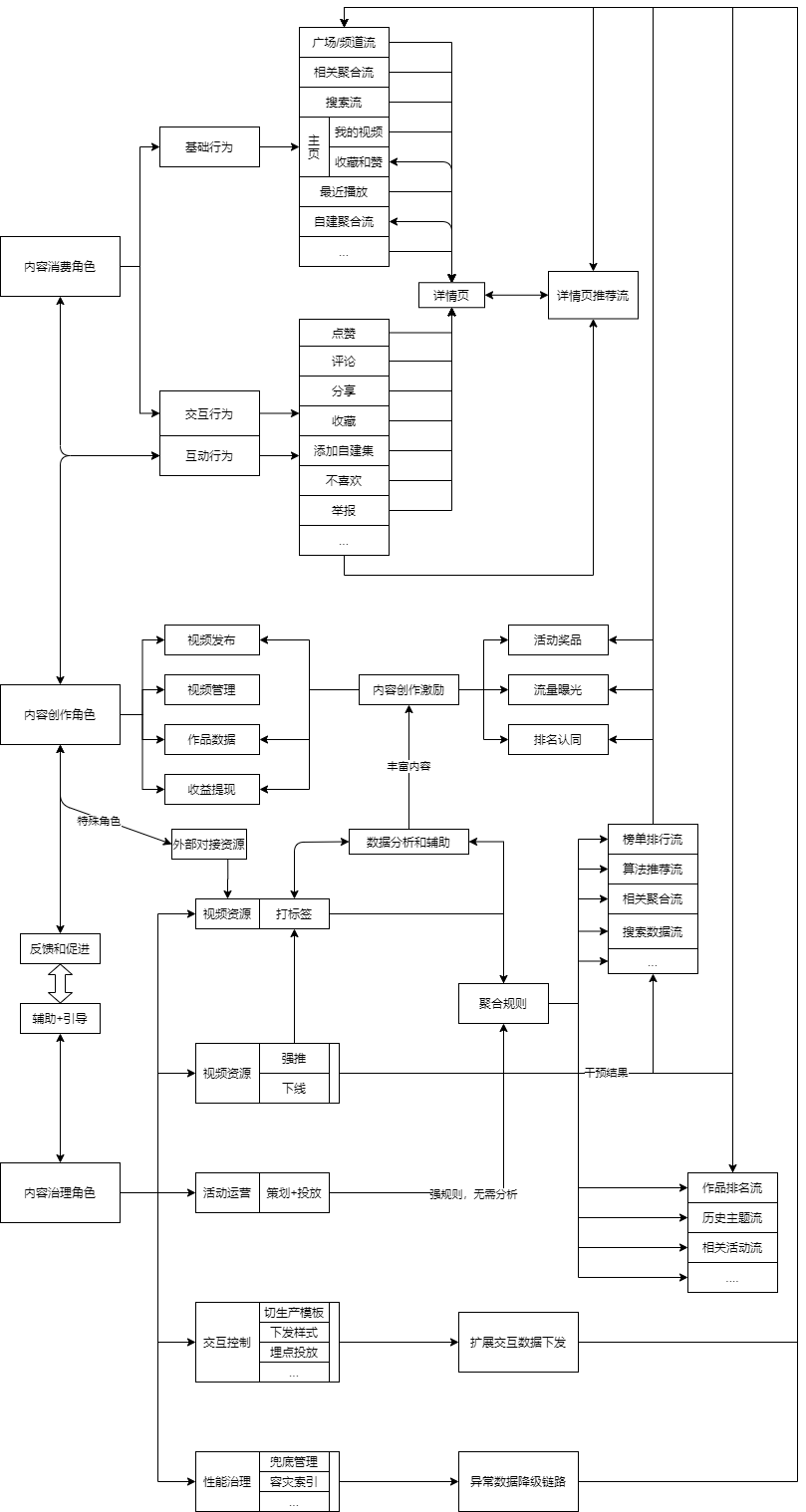
角色行为流程简图(初版)
领域数据
- 用户数据(用户)
- 资源数据(资源、资源-用户、资源-资源)
- 交互数据(资源-用户-行为)
- 互动数据(用户-资源-用户、用户-功能-用户)
- 治理数据(资源-标签-规则-场景,资源-资源)
- 分析数据(策略分析-算法推荐、统计分析-报表排行、行为分析-产品决策)
1、一个领域内数据主题就是对应的领域资源和用户。
2、资源和用户通过一系列行为和关系形成各种组合数据。
3、资源数据、交互数据和互动数据存在笛卡尔积的组合,是数据爆发式增长的核心,也是社区增长的主要重心。
资源数据
资源数据是用户使用产品自主创作的内容。
1、资源数据是内容的核心。
2、资源与资源的关系是网站流聚合内容的主体。
用户视频领域主资源数据结构
主资源由于其在产品领域上可能会有不同表现形式或历史原因,需要区分设计,故也可能有完全不同的数据结构和流转模式。
为了在视频领域上可以灵活扩展,甚至在迭代上互不影响,需要定义类型,能够有效做到业务隔离和数据聚合。
比如视频可能有:
1、用户产出视频(VLog)
2、歌曲 MV(包含付费)
3、知识付费课程(专题视频)
4、演唱直播等 Live 录制视频(包含付费)
5、外部渠道同步视频
6、...

用户视频领域主资源相关资源关系数据结构
主资源相关资源在产品方向是一个很好的维度聚合页,其二次生产可以产生大量优质内容。
聚合页依赖于维度,把每种维度即为一种相关资源,例如:
1、歌曲相关视频(歌曲)
1、歌手相关视频(艺人)
1、达人相关视频(用户)
2、主题相关视频(主题)
3、位置相关视频(位置)
4、频道相关视频(频道)
6、热度相关视频(播放/点赞/收藏/评论)
7、...
发布行为、交互行为、数据分析、算法分析等产生的维度数据
统一可以定义为主资源的相关资源,相关资源=维度数据+维度类型=唯一的聚合资源
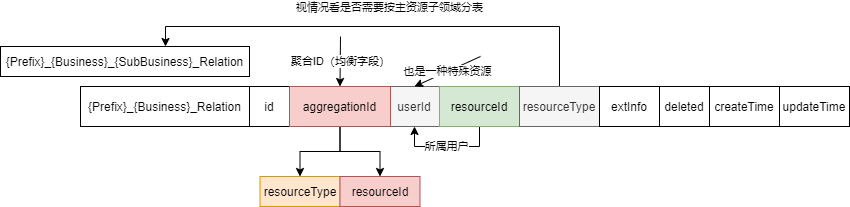
用户视频动态数据流数据结构(泛资源数据结构)
泛资源本身并无丰富的业务,其虽有通用的业务模式,但是核心业务是主体信息,而主体信息是其所关联的资源。
任何一个独立产品基本都有这种泛资源,其表现上就是评论、动态、私信等等。
以云音乐为例:
主体信息是音乐,则出现《歌单》、《排行榜》等等;
主体信息是声音,则出现《播客》;
主体信息是演唱,则出现《K歌》
主体信息是直播,则出现《LOOk直播》;
主体信息是视频则出现《云村》;
...
交互数据
交互数据是用户和资源互动产生的数据。
1、交互数据核心在用户,用户操作才会产生。
2、交互数据扩展点在行为,行为设计要旨在降低行动成本,促进用户习惯养成。
3、交互数据重心在资源,资源的质量或热度决定了交互数据的增长和总量。
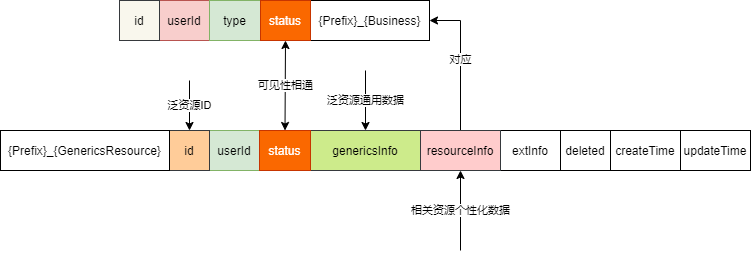
用户交互行为关系统一数据结构设计
用户交互关系数据记录主要把握三点:
1、重要维度保证:用户、资源、交互
2、重要维度扩展:用户(唯一ID|ID+类型)、资源(唯一聚合ID|ID+类型)、交互(类型)
3、重要维度描述:【用户】-【行为】-【资源】-【发生时间】
当然,由于 UGC 的体量极容易膨胀,在维度侧可以做适当分表,同时保证该维度细分业务数据隔离,比如:
交互类型作为分表名变量:{Prefix}_{Business}_{Action}_Relation
资源类型作为分表变量:{Prefix}_{Business}_{ResourceTypeName}_Action_Relation
以下用交互类型分表为例,做通用交互关系数据设计。
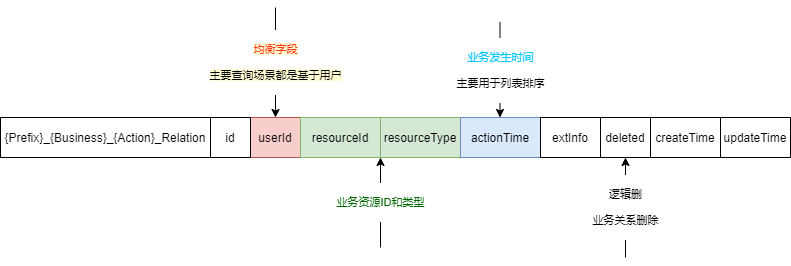
用户交互行为关系计数灵活数据结构设计
计数我们可以理解为一种数据统计,在关系数据库可以简单理解为对记录数的 COUNT(*)
对于 UGC 场景,数据体量巨大且伴随高频访问,实现上不允许实时 COUNT,要求我们要对这种统计做存储————计数表。
由于 COUNT(*) 在数据分析里面是一种聚合行为,其存储结构=聚合Key+COUNT(*)
一般情况,聚合Key=维度的组合:
1、用户交互行为关系计数对应聚合Key=用户+交互行为
2、资源交互行为关系计数对应聚合Key=资源+交互行为
通常我们在设计表的时候会把交互行为设计成表中的字段,故一个用户交互核心计数表一般如下:
+-------+-----+--------+--------+------+
|userId |like |collect |comment |share |
+-------+-----+--------+--------+------+
|10010 |400 |20 |50 |10 |
+-------+-----+--------+--------+------+
当我们想添加新的交互,比如一键三连、观看心情、投币等等。
需要在表上添加新字段,这对于大表是不够友好的,也会造成物理存储上不连续。
同时当我们对表记录计数进行修改,记录维度集中情况容易锁行,影响写性能。
因此,为了便于扩展和保持性能,计数表可以通过维度数据冗余,将一行多个交互计数转成多行交互计数 ↓

同理,资源维度聚合计数灵活数据结构设计

综上,要达到便于扩展和可插拔,采用组合维度计数 ↑
- (actionType) 可以随意新增用户行为业务,而不用一开始就定义最全的各种行为计数列
- (resourceType) 可以随意废弃或新增某种资源而不影响原先数据层的计数数据和逻辑
- 用户维度计数行转列,分散了计数记录,降低记录热点 SQL 概率
互动数据
互动数据是用户之间互动产生的数据。
1. 互动数据的核心在承载互动关系的产品/功能/活动,表现形式在用户之间。
2. 互动数据的扩展点在互动事件,互动事件可以大到一个产品、小到一个具体功能或某个活动。
3. 互动数据天然具有可重复性,互动的频率决定用户的粘性,是增长用户渗透率的核心方向。
【扩散】:评论作为通用交互信息,作用用户与资源,也可以直接作用用户之间,对 UGC 内容起主动扩散作用。
评论是一种泛资源,不同资源依托与它而拥有评论功能。
对资源进行评论,这是资源的常用交互,并不能算是真正的互动。
对于评论的回复,可以直接关系到两个用户之间,我们定义为一次互动。
社区的活跃度除了体现在交互频次(UV),还应体现在互动的频次。
互动频次越高,社区活力越大,社区潜能越大,社区发展越健康。
回复这种行为在评论术语里面定义为:盖楼。
盖楼行为可以在用户与用户之间反复的叠加,成功将 用户-内容(资源)-用户 联系到一起,从而放大内容的影响。
【联系】:私信作为一般产品都有的互动,是用户对用户更加直接的联系。
私信也是一种泛资源,不同角色互动对应不同内容(资源)。
私信由于作用在两个用户之间,内容不公开,无法扩散。
1、官方-用户:活动和推广私信,类似于公告、周知。
2、创作者/大V/好友-用户:创作者作品推送、大V动态推送、好友动态推送。
3、用户-运营:用户主动的问题反馈,这里对应的内容可能就是产品本身功能或资源内容的疑问和反馈等。
4、...
【热点】:活动作为官方发起的事件,具有最好、最丰富的流量支援,很容易创造站点内的热点内容。
活动是一种最为灵活的泛资源,具有很强的时效性。
在时间限制、流量加持和金钱成本的笼罩下,出场自带光环,很容易调动用户积极性。
UGC 活动一般有如下方向:
1、激励创作(竞争排名奖励类活动、日更奖励活动)————伴随金钱成本
2、用户行为习惯养成(新功能衍生出的挑战类活动)————伴随等级和积分、金钱成本
3、打造产品特色(日常特色活动)————伴随排名榜单、金钱成本
4、保证社区活力-UV ↑(论坛活动、线下活动)————伴随较大运营成本和金钱成本
5、...
治理数据
治理数据是运营在资源管理行为下产生的数据。
治理数据核心在资源数据的分类,表现在资源数据的良性竞争————优胜劣汰。
治理数据的扩展点在效能提升和控制提升,包括分类效率、策略适应、安全把控等。
治理的目标是实现 UGC 生态最大化良性运作,让好的内容更快扩散,让坏的内容无法传播。
【标记】:打标是常见运营行为,通过对资源标记特征词、特征位、特征状态,达到资源分类的效果。
标记数据最易实现的则是特征位和状态位数据,因为他们含义明确。
最可以进行挖掘的就是特征词类文本数据,一般分为机器打标和人工打标。
文本识别、图片、音频和视频等多媒体内容识别技术可以初步通过机器审核,进行标记。
人工是最后一道防火墙,并且人工能有更多人性化的标记,所以说每个打标运营都是一个鉴美师。
【筛选】:筛选也是常见的运营行为,一般是通过创建固定规则(高级查询语句),选出符合条件的资源。
筛选出来的结果在运营术语中称之为资源池,常见 UGC 有如下资源池:
1、推荐池
2、精品池
3、特色池
4、...
这些池子数据产出后,需要通过分发渠道实时或延时到 C 端投放。
而据我所知,一个熟练的运营的痛点应该就是有时不能马上让自己的筛选结果生效,因为她们总问————什么时候生效。
【控制】:控制主要是对 C 端效果的直接干预,并可以实现即时生效。
控制主要通过强推和屏蔽即时干预 C 端页面:
1、强推:立即曝光优异内容、新功能、广告等
2、屏蔽:马上淘汰劣质资源、负反馈功能、业务风控等
分析数据
分析数据:不同的角色通过已有的各类数据,进行不同目的的数据挖掘后产出的具有实际有意义的数据。
这些数据常规可以被划分为:统计数据、决策数据和算法数据。
分析数据在实际应用迭代过程中起着立竿见影的效果,往往随着其应用规模的量级化起着爆发性效果。
而这些优质的分析数据决定着应用的迭代方向、内容的良性淘汰和扩散效能,以及长期发展的步调。
【统计】:统计数据属于一种静态数据分析,数仓工程师通过固定规则组合各种数据挖掘操作,生成不同维度数据报表。
数仓工程师通过 SQL、Hive 或Scala 等脚本对数据进行处理,主要数据挖掘手段(OLAP):
1、切片&切块:维度细化(Select A,B & Group A,B)和 维度组合(Select A,B & Group A,B,C)
2、旋转:行转列或列转行
3、上卷:聚合操作(Group、Partition、Sum、Count、Max、Min、Avg等)
4、下钻:维度拆分(笛卡尔、Join、Union)
5、其他:公式计算(开根号、平方差、对数等)、文本解析(字符转换、Json解析、Xml解析等)、取反向等等
数据集市与数仓:
1、数据集市:处理好的数据进行各种业务和领域范围分类,让其他相关内容治理角色随取随用。
2、数仓:数据集市的总和。
数仓的发展:
1、目标是自动化。数据被处理成所有可用维度,可以轻松获取和加工。
2、极限是实时变化。既通过时序数据库等垂直数据手段可以实时纠正细小数据变更影响的统计数据变更。
【决策】:决策数据是对统计数据的一个专业化的趋势预测,主要是策划和运营通过数据决策产品迭代方向和营销方向。
用于决策的数据很多,其中比较重要的数据:
用户行为日志:策划、运营和算法常用的决策数据,识别用户习惯和规划出好的功能让应用用户更愿意花时间使用。
不同 APP 界面结构不一样、目标用户不一样,会形成决然不同的 UA 日志。
内容和交互统计数据:是运营常用的决策数据,识别和营造相应的环境引导有助于促进好的内容产生。
视频而言,重要的数据总是播放量、点赞量、评论分享量以及发布量等等。
相关资源数据:在早期丰富产品功能和提高曝光重要决策数据,通过提高覆盖率来增加曝光率。
目前各大知名 APP 都在涌入视频市场,不同产品的早期的创造者视频相关资源侧重点不同,比如:
云音乐更关注歌曲覆盖率
微博更关注热搜词覆盖率
知乎更关注话题贴覆盖率
淘宝更关注商品覆盖率
快手更关注乡土风俗覆盖率
抖音更关注社会热点覆盖率
B站更关注优质动漫覆盖率
...(以上部分或许)
决策后的趋势预测一般需要通过数据在时间窗为维度的统计数据,这也决定数据的统计有一定粒度的时间维度(一般按天生成统计数据)。
趋势曲线如果有很多尖锐波动的折线,决策上需要让折线朝良性方向波动。
趋势曲线如果起点低且非常平缓甚至下滑,需要通过一剂猛药,来改变场景下的一潭死水或者砍到该场景。
趋势曲线如果起点高且非常平缓,需要通过其他维度数据提升(如用户量或优质视频总量)来带动提升。
总之,让有限的时间和开发资源,尽可能提升视频维度数据的体量,使得站内环境下达到一个良性饱和的状态。
决策需要有一定的合理性。比如:
日活只有 10W 的应用,让它实现 1 亿的日播放量目标,这样的要求无异于败而求战。
因为,一个人如果每天看 1000 个视频,每天要看废 10W 个人。
【算法】:算法数据是面向用户的一种决策数据,主要通过算法构建计算模型并使用统计数据和实时数据动态打分和排序出来的数据。
算法数据更关注模型分计算的准确度,通过某个业务场景特性构建计算模型,比如:
1、歌手A在本站受欢迎程度 R(x) 在公网知名度 r(x),其拥有曲风B的歌曲C
2、不同年龄对歌手A的访问比率 f(x)
3、不同年龄在曲风B的每日被听完概率 s(x)
4、视频V有歌曲C的配乐,配乐相关系数 p(v,c)
5、计算用户U对视频V的感兴趣分计算模型:(10 * R(A) + r(A)) * f(U.age) * s(U.age) * p(V,C)
上面是一个假设的计算模型,通过每天或每小时计算所有用户对每个视频的感兴趣程度,得到一份依据某些维度数据的兴趣分值。
兴趣分值可以作为排序依据,从而形成算法推荐的依据之一。
算法的发展:
1、目标是准确性。无限接近且预知现在用户想看什么,并达成良性循环。
2、极限是实时性。未来不可预知,现在才是关键。实时性依赖算法实时策略和计算模型的数据质量。
曝光是一种很直接的实时策略,数据实时上报可以立马让分值变化,比如:
1、原分值 S
2、当前时间戳 nowTimeStamp
3、曝光时间 seeTimeStamp
4、当前分值:S - 1000 / (nowTimeStamp - seeTimeStamp) 或 (1 - 1000 / (nowTimeStamp - seeTimeStamp)) * S
参考文档:
- 互联网专业名词:https://zhuanlan.zhihu.com/p/52712121
邀请标记你的阅读体验😉 | →