装饰模式深入和非重构型迭代范式讨论
从 I/O 谈起
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,
流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
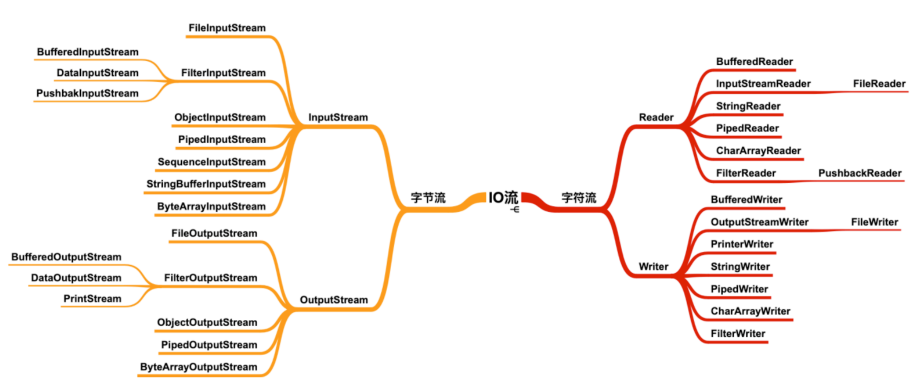
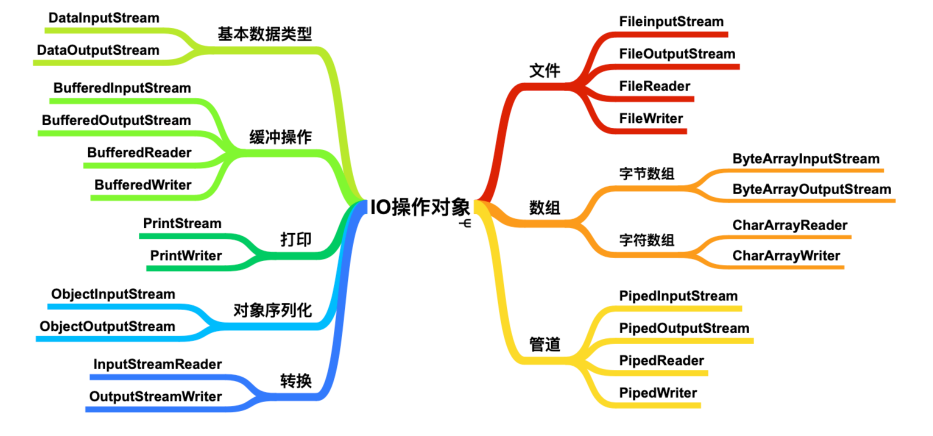
流按操作数据分为两种:字节流与字符流。
流按流向分为:输入流(读),输出流(写)。
字节流+编码表 --> 字符流
字节流的抽象基类:InputStream 、OutputStream。
字符流的抽象基类:Reader 、Writer。
new BufferedReader(new InputStreamReader(new FileInputStream(new File(filePath))));
↓
文件 --> 原始 IO(字节流)--> IO 字符流 --> 缓冲区(字符数组) --> Java IO 中的设计模式(装饰设计模式)
↓
单机应用(文件流/缓冲流/管道流) --> B/S 单服务(字符流/打印流)--> 多服务/微服务/RPC(序列流/对象序列化流)--> 云(信息流/密码流)
↓
业务数据流(比如 Feed 流 --> 场景数据流) --> 业务迭代(业务数据流的迭代和扩展)
装饰模式
装饰器模式又名包装 (Wrapper) 模式。装饰器模式以对客户端透明的方式拓展对象的功能,是继承关系的一种替代方案。
应用场景:
- 需要扩展一个类的功能或给一个类增加附加责任。
- 需要动态地给一个对象增加功能,这些功能可以再动态地撤销。
- 需要增加由一些基本功能的排列组合而产生的非常大量的功能。
1、继承属于扩展形式一种,但不见的是达到弹性设计的最佳方式,组合优于继承。
2、行为可以被拓展,而无需修改现有的代码。
3、可以使用无数个装饰者包装一个组件。
4、装饰者会导致设计中出现许多小对象,如果过度使用,会让程序变得很复杂。
非重构型迭代
重构往往意味着极大的调整底层逻辑,是人力和时间的黑洞,往往是互联网迭代不推荐的做法。
何为非重构型迭代?
在业务迭代过程中,底层逻辑不适用,这时候需要重构底层逻辑才能适配新业务,往往事与愿违。
1、时间不允许(迭代上线卡点,时间和人力不足)
2、重构风险不允许(同样是时间和人力的协调)
此时,为了快速推进迭代,实现业务目标,我们往往选择 Case 迭代:
1、添加新的参数(xx 场景参数)
2、添加新的判断(xx 场景下调用 xx 场景处理函数,返回)
3、测试/提测/上线 --> 完美!
↓
for(i++ < 100) {
Case 迭代;
}
【可读性累积下降】擦,99 个 Case,看吐了,代码传错一个参数都会爆炸的感觉。
【重构复用率降低】擦,终于有时间重构了,Case 迭代原来统一逻辑都变了,感觉代码都不能复用呀,看策划能否再给我一年时间?!
↓
1、CR 无法轻易解决:代码逻辑自洽,小段 Case 处理不影响,加之重写时间成本 --> 无法驳回
2、个人编码无影响,集体迭代 n 次后与设计初衷偏差,逐渐放大风险 --> 迭代成本放大
一般情况,一个功能经过这种【通过添加代码块分支的方式】达十次后的小迭代,业务函数长度将超过一屏展示长度(50 行)。
非重构型迭代范式讨论
迭代按照编码实践可以分为:
- [增] 新增功能,功能叠加
- [改] 修改老功能
- [删] 删减功能
- [重构] 代码收束整理
[增] 新增功能:二元嫁接
二元嫁接的思路就是:
- 假设原先业务类为 Vx
- [增] 每次新迭代新建一个版本类 Vx+1
- [增] 为新增功能添加服务类 Vx+
- 当符合新功能场景调用 Vx+,否则调用 Vx
↓ Vx+1 / \ Vx Vx+ - 这样,老业务兼容,新业务隔离迭代,【嫁接节点】作为新老业务合并节点
- 【嫁接节点】就是新开的调用入口,老业务入口依然保留
↓ ↓ ↓
v0 v1 v2
/|\ --→ / \ / \
A B C v0 v0+ --→ v1 v1+ --→ ...
/|\ / \
A B C v0 v0+
/|\
A B C
[改] 修改老功能:换新叶
从上面二元嫁接的示图上,大家可以看到真正的业务功能是在【叶子节点】,而哪些【嫁接节点】仅作为粘合功能的过渡节点。
- 【叶子节点】: 具体业务逻辑实现
- 【嫁接节点】: 组合功能并对外透出业务功能
所以,换新叶的思路就是:
- 假设需要修改的业务是 X 类
- [增] 添加 X 类的拷贝 X' 类
- [改] 可以完全复制,也可以 组合/继承 X 类,做修改调整
- 替换对应【嫁接节点】上类的注入 X -→ X'
↓ ↓ ↓ ↓
v0 v1 v2 v2
/|\ --→ / \ / \ / \
A B C v0 v0+ --→ v1 v1+ --→ v1 v1+' --→ ...
/|\ / \ / \
A B C v0 v0+ v0 v0+
/|\ /|\
A B C A B C'
[删] 删减功能:剪枝或空服务替换
删减功能本质上是去掉对应的业务功能,也就是迭代树上面的【叶子节点】。
↓ ↓ ↓ ↓
v0 v1 v2 v2
/|\ --→ / \ / \ /
A B C v0 v0+ --→ v1 v1+ --→ v1 --→ ...
/|\ / \ / \
A B C v0 v0+ v0 v0+
/|\ /|\
A B C A B C'
由于增量是二叉树形态的迭代,若被删除【叶子节点】的嫁接节点无两个以上的分支其实已经可以剔除。
↓ ↓ ↓ ↓
v0 v1 v2 v2
/|\ --→ / \ / \ / \
A B C v0 v0+ --→ v1 v1+ --→ v0 V0+ --→ ...
/|\ / \ /|\
A B C v0 v0+ A B C
/|\
A B C
故剪枝的思路就是:去掉【嫁接节点】对应删减功能分支逻辑块或替换 父父【嫁接节点】的 子【嫁接节点】
空服务替换逻辑类似,不破坏原有分支链,替换【嫁接节点】的 叶子服务类 为 空实现服务类。
↓ ↓ ↓ ↓
v0 v1 v2 v2
/|\ --→ / \ / \ / \
A B C v0 v0+ --→ v1 v1+ --→ v1 ○ --→ ...
/|\ / \ / \
A B C v0 v0+ v0 v0+
/|\ /|\
A B C A B C
[重构] 代码收束整理:二叉树 -> B+树
使用装饰模式的增量迭代过程中,虽然在每次迭代时逻辑非常清晰,但不可避免造成过长的调用链和过于分散冗余的功能服务类。
所以,[重构] 也是不可缺少的一个迭代步骤。
功能重构不像系统重构,它并不能总依赖足够多的时间和人力,以及足够完善细致的测试支撑:
- 稳:功能不能变化
- 快:时间线不能拖太长
- 简:可读性要有提升,逻辑要简洁化
综上,二叉树 -> B+树的思路就是:
- 不动任何【叶子节点】类,保证各个闭环业务逻辑稳定
- 快速剪枝【嫁接节点】类
- 将所有【叶子节点】有逻辑且有序的编排到一个新的【嫁接节点】类下
↓ ↓ ↓ ↓
v0 v1 v2 __v3__
/|\ --→ / \ / \ / | |\\
A B C v0 v0+ --→ v1 v1+ --→ V1+ V0+ A B C -->
/|\ / \
A B C v0 v0+
/|\
A B C
当然,如果我们能从重构某业务的过程中整理一套该业务通用简洁的迭代公式,那么后续迭代可以参照使用。例如:
- 统一参数,可以依情况使用多态衍生的设计模式(参考此前函数式编程)
- 统一全集可能 Case 组,可以用代理切面策略模式或者 Switch+多态
- 其他(参考 MECE,做到公式子块相互独立且完全穷尽)
此外,重构迭代者整理好对应文档或编码时候备注好注解的话,后续人员依此迭代,可以保证编码风格或逻辑的统一。