Word、PDF 解析项目(二)
前情提要
前面说了一个偏技术方向的文档解析类的项目,当普通人看到那些五花八门的文档情不自禁就会把项目结果,想象成构造复杂、难以理解、代码高深的集合体。其实,说实话,在没有去了解具体的文档和内容的时候,我心中也是没有底的一个情况,毕竟这种没有限制的文档文本,穷举法是不切实际的做法,但是当你着手去设计的时候,越来越发现,其实,并不复杂。当然,不要急着去编码,第一步的思考总是错的(模板),而第二步思考往往就是正确的方向,如下是我对这个项目的一个比较完整的设计思路,大部分是在解析方面用到的工具。
解决文档结构的差异
Word、PDF 在文件结构上的结构有所不同,就连 Word 家的 Doc 和 Docx 也大不相同。然而想要解决这种差异,作为总是接触 Web 项目的工程师,情不自禁的就想:把他们全部转成 HTML 格式。
我们都知道,其实映入我们眼帘的 Word、PDF 文档在视觉上是二维的一个结构,如果有不是太合法规矩的 Word 文档会有悬浮的文本框和图片,这貌似又变成了"三维“的文档了。但是 HTML 文档我们都清楚,如果我们能有效的解决了代码里面的浮动,文本的结构可以看成是一维的结构,文档拉成字符串的顺序和我们阅读的顺序一模一样。
1)、DOCX 使用 org.apache.poi.xwpf 转成 HTML
a)、加载文件 DOCX 文件流,创建解析文档
document = XWPFDocument(文件流:InputStream);
b)、针对图片,创建额外的解析器
XHTMLOptions options = 图片解析器(图片输出路径);
c)、定义输出流(out),转化输出
XHTMLConverter.getInstance().convert(document, out, options);
2)、DOC 使用 org.apache.poi.hwpf 转成 HTML
a)、加载文件 DOC 文件流,创建解析文档
document = HWPFDocument(文件流:InputStream);
b)、针对图片,定义图片管理器
WordToHtmlConverter.setPicturesManager(PicturesManager)
c)、解析 DOC,转化输出
htmlDocument = WordToHtmlConverter.processDocument(wordDocument);
Transformer(htmlDocument,out);
3)、PDF 使用插件 pdf2htmlEX 转成 HTML
Windows 通过 Runtime.getRuntime().exec 执行插件,产生的输出流写入转化文档
Linux 需要安装 pdf2htmlEX 脚本,同理通过 Runtime.getRuntime().exec 执行命令解析
转化的图片地址为 base64 位字符串,需要将其转存图片
以上提到的具体代码,请根据标题自行百度学习 ( • ̀ω•́ )✧
切块:反正都一样,但是小的更好
呀,通过上面的步骤,终于不用打 Word、PDF 文档了,他们已经全部变成了 HTML 文本了 ( ̄▽ ̄)。
这个时候有人跳出来了,说:下面就简单了,这就变成了一个爬虫抓取问题了,这个我会。
但是,真正做了上面转成 HTML 文档的人才能看出来,真正的难题才刚刚开始。总所周知,爬虫是根据某些网站的 HTML 文档的某些标识、属性、结构进行数据提取,然而解析出来的 HTML 没有 ID、class 以及特殊的属性,结构上也是没有规律的各种嵌套,甚至“相同"的文档,解析出来的 HTML 在 HTML 结构上会略有不同,虽然浏览器打开的 HTML 界面结果是一样的。而且,前面讲到不同旅行社、计调产出的风格不同,转成的 HTML 也是截然,相当于爬虫解析不同的网站,这样要定制不同的爬虫规则,和做模板大同小异,又回到穷举问题。 (:з」∠)
当然,解决问题才是关键,不能既提出一个无解的问题,又不思考和实践解决方案。文档有两个至关重要的特点:
- 人做的
- 旅游相关,准确点是和线路行程相关
人是一种逻辑思维动物,人做的文档有上下文关系,这和机器生成的随机码不一样,这是一个重要特点,上下文关系。旅游线路行程相关,这就有了行业特点,缩小了解析范围,行业特点就我们系统而言是可以进行穷举的,在模块上。综上,就是:可穷举的有上下文关系的旅游行业的线路行程的 HTML 文档。
于是,可穷举就有一个最小单位,我们可以将一个大的 HTML 文档,通过穷举的项和上下文关系特性,将其切成一个个 HTML 文本小块,这就是文本切块的工具原理,穷举就是文档中的小标题关键字。
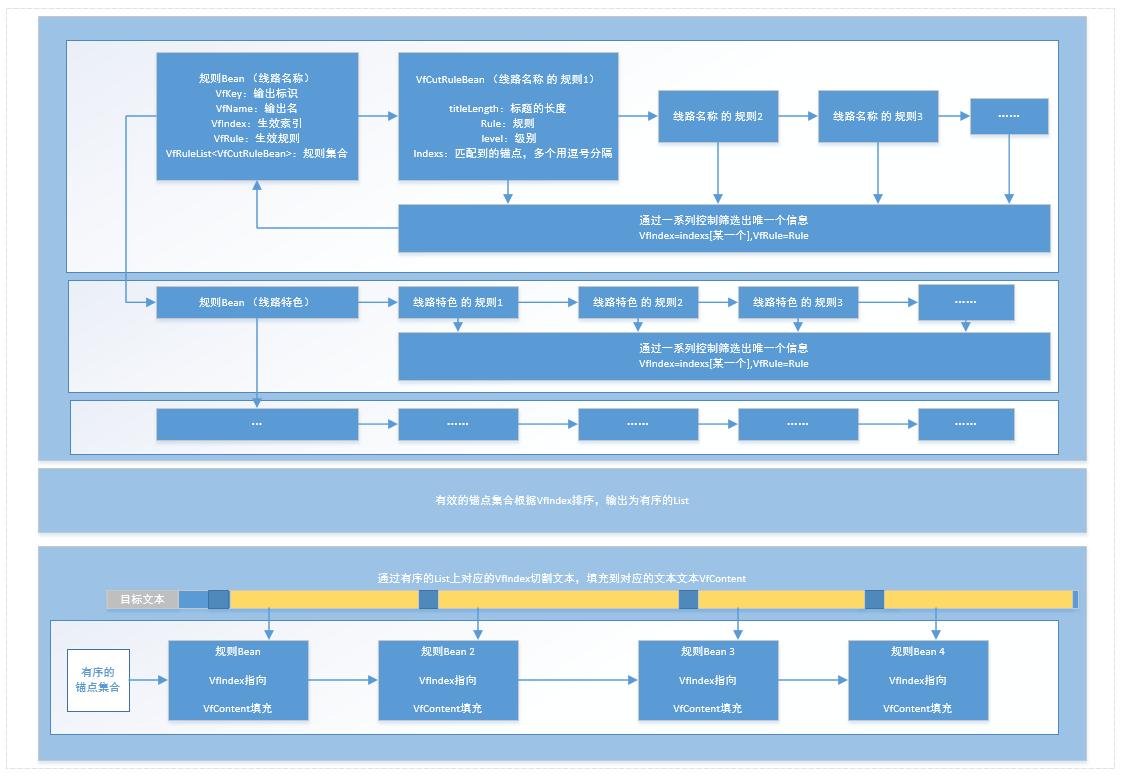
当然,这上面的锚点有效性的定义上还要解决一些问题:
-
标题被标签分隔。在文档转 HTML 的时候可能在文本逻辑上被不换行标签(span、label)等分隔,或者还有某些文档标签由于制作者的粗心会有空格特殊字符等夹杂其中,亦或者文档的标题结构是竖着排的等情况。而这些情况都需要在切块之前处理好。所幸,这些都是在程序允许范围内可以有效杜绝的。
-
正文中可能含有标题关键字。这种情况下,在上面处理了随机出现的不换行标签后,整行的文字就在一个标签里面了,可以根据 HTML 标签成对的闭合性,计算出关键文字占所在的最近父标签内总文字的百分比,百分比高者一般就是真正的标题,也就是正文开始的地方。而这个方法也是切块算法的一个重要成分,叫容占比高优法。
找到正确的锚点之后,然后根据锚点排序,就可以有序的将文本切成一块块的小个体,如果过程中做好分类,还可以将相似的块合并。切块之后,大的文本变成了小的文本,小文本特征更加单一明确,数据提取更简单。不过还是有很多问题,比如上面的切块是属于一种非常暴力的方式,导致很多标签残缺,特别是像表格这种组合标签,需要先进行修复才能后续的正常解析和用于显示。
Jsoup:学会 HTML 的正确打开姿势
既然前面一直是基于 HTML,那么 HTML 的特性 DOM 需要好好利用起来。java 的 HTML 解析器目前比较出名的像 Jsoup、Xpath 等,不过由于 Jsoup 语法更接近 JQuery,所以我选择了 Jsoup。利用到 Jsoup 后,文本就可以一口气变成一个 DOM 元素集,可以进行很方便的元素扣取,特别是对表格和图片的处理,简直如有神助。当然,要把它变成一个工具,需要先让他很流畅的支持批量提取数据的功能。
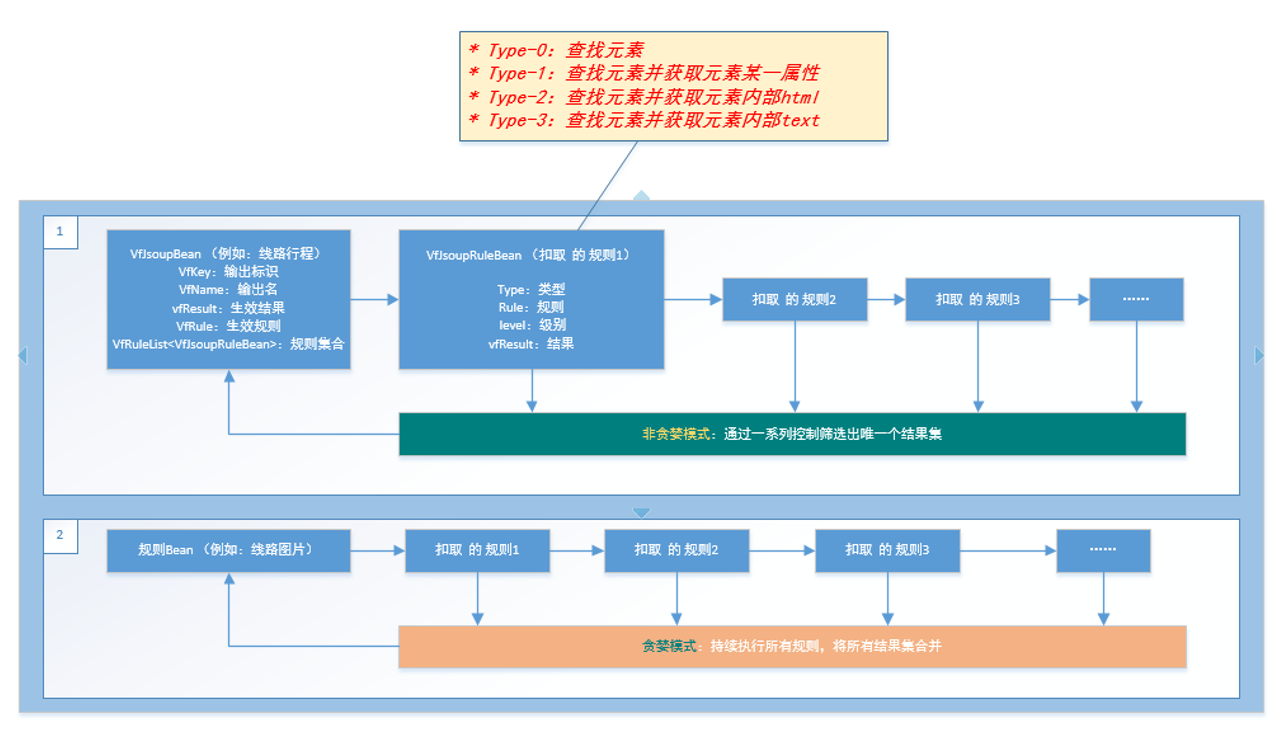
从该工具中衍生了一套表格数据处理的方法,包括错位表格、跨行、跨列表格数据的定位和提取。
正则:更快更精确还可以模仿招式
我们都知道正则源于文法重点 3 型文法,对应于有限状态自动机,好吧,我们或许不知道(点击了解)。所以,我们对正则算法的匹配效率不需要过多讨论,反正要达到类似的效果正则是比较高效的。然而,我们知道 java 的正则表达式真正耗时的不是索引取取数据的时间,而是用正则表达式 compile 文本的时间,有效的减少正则的 compile,就需要简单的对原来的正则表达式进行封装,让离散的数据一次性的变成有效的数据集。
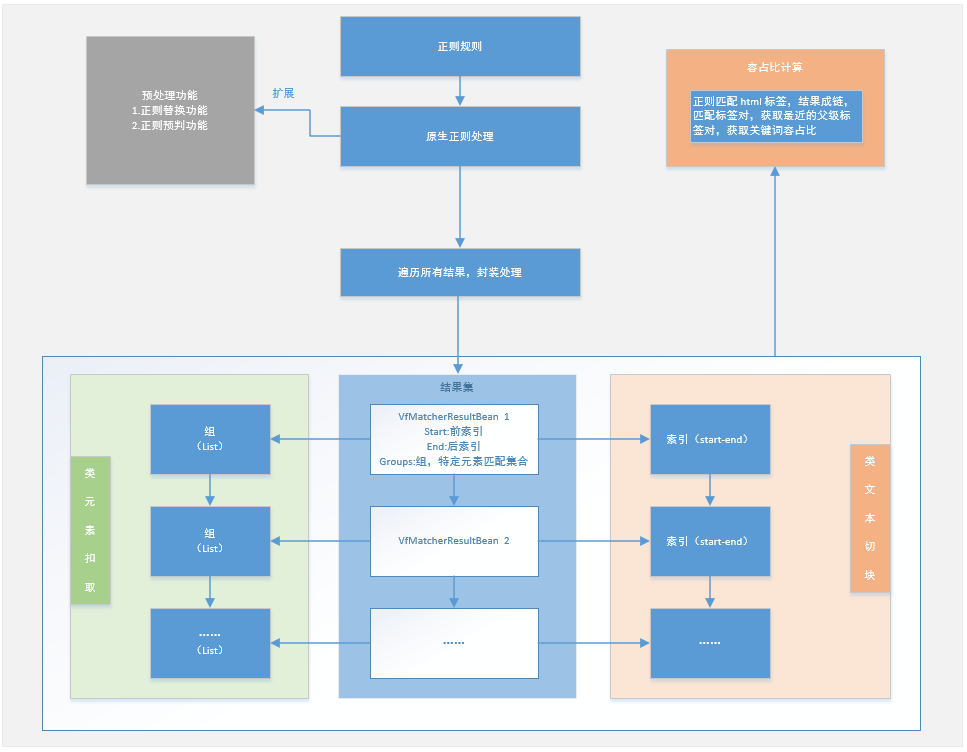
正则除了可以做复杂的预判和替换外,批量匹配的正则单元具有开始结束索引和组的这两个重要的特征。索引可以模仿切块功能的锚点,实现更为复杂的切块,比如行程信息中精确到每天的行程信息解析,就是利用这种变形版的正则切块法,直接有效区分解析非表格风格的行程,当然也可以针对表格风格的行程(不过一般情况下,表格风格的行程用 Jsoup 解析效果更佳)。组就相当于提取到的有效数据,是一种更加自由的元素扣取,不用像 Jsoup 这样,要规范的 HTML 文本才能有效扣取。另外,切块中的容占比计算也用到了正则工具。
用点分词和聚类
当大部分数据都出来了之后,我们就要精雕细,处理那些顽固数据。例如,线路行程里面的城市数据,这种无法方便穷举的城市数据匹配,对词这个最小单元要有很高效的解析,而且还要是城市的单词。幸好我们公司有 Elasticsearch,旅游方面实现了针对我们库的一个城市提取服务。当然,这个项目的内部我也添加了 Lucene 分词,用于备用情况下生成某些有概括性的语义小标题,结合 2012 年的 IKAnalyzer 可以达到每秒 600 万字的解析量,解析时间可以忽略不计。
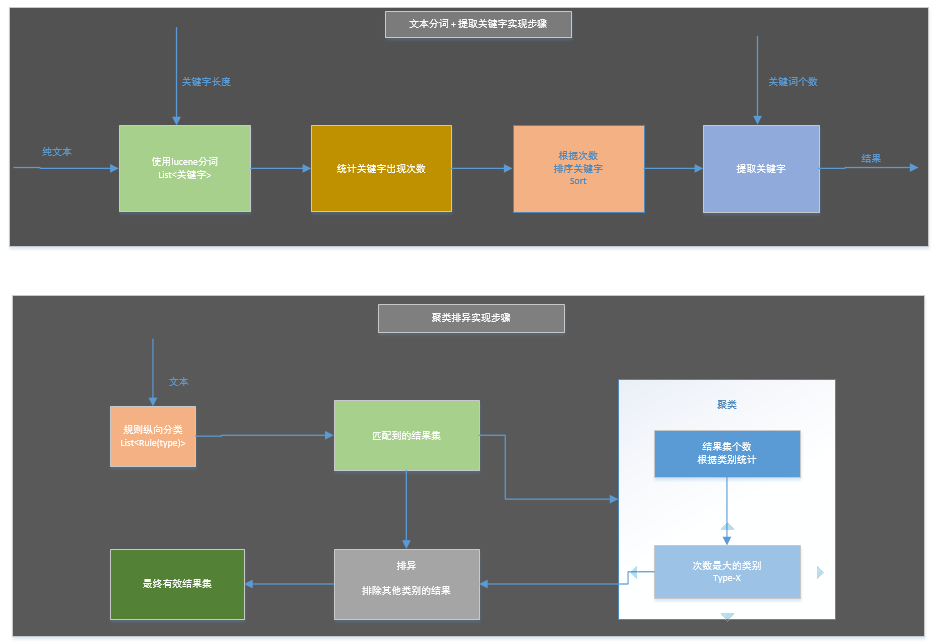
聚类,貌似牵扯到了一点点数据分析,其实用到它只是为了解决一个比较关键的问题:那就是确保行程数据按天为单位可以达到连续有效。对于行程数据,这种极具统一风格的信息,我统计出了近 10 种风格,但是这是人做的文档,一般情况下风格都是相同的。加之容占比排除等等的作用,可以很有效的提取到每天的行程。然而,如果正文中出现了其他行程如何处理,恰恰这种时候容占比也不能排除(非表格格式的行程信息多见)。就好比我们用正则切块匹配到了多种风格的锚点,这样就会打乱锚点的顺序,第二天和第三天中间多了个“第 5 天”,第三天和第四天之间多了个“第 1 天”,聪明的我们已然了解到需要排除“第 5 天”和“第 7 天”的这两个数据,他们的风格不对。而聚类就是统计这些风格出现的次数,次数高者得胜,其他淘汰。
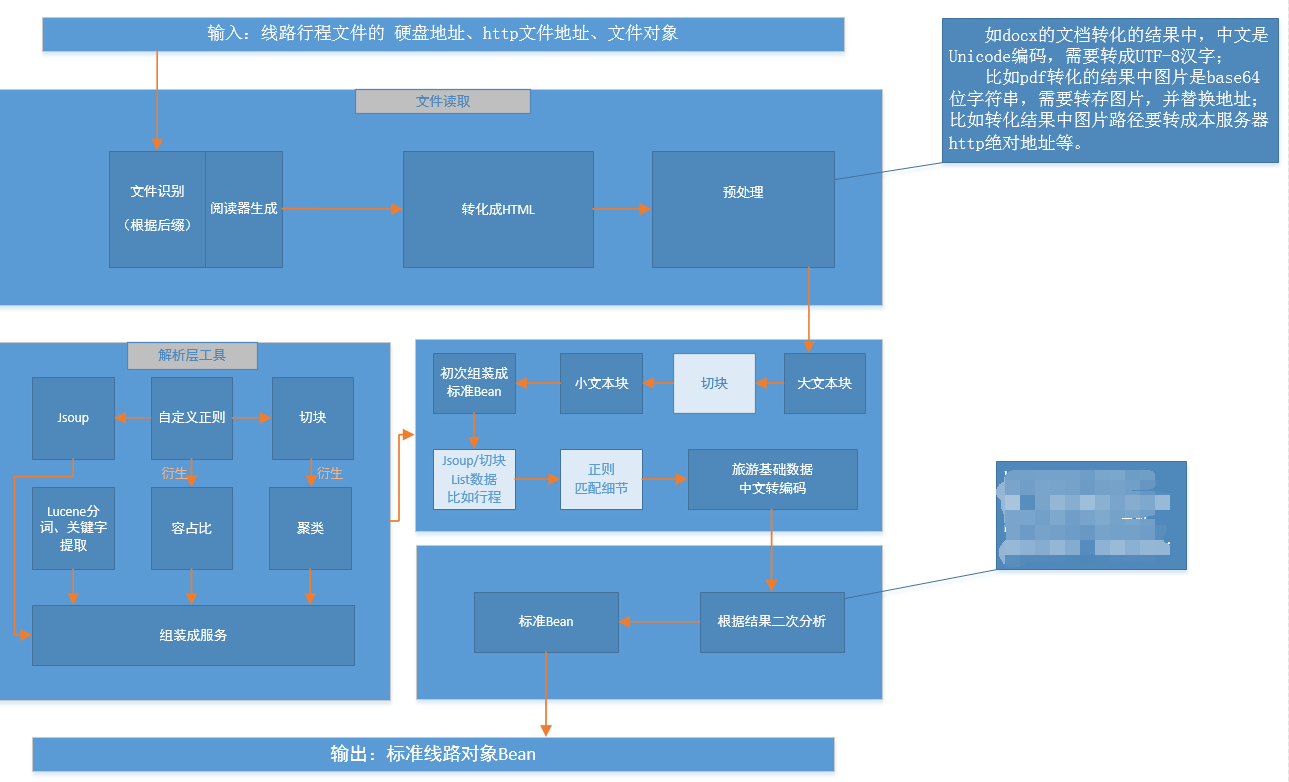
细节解析数据流向简图
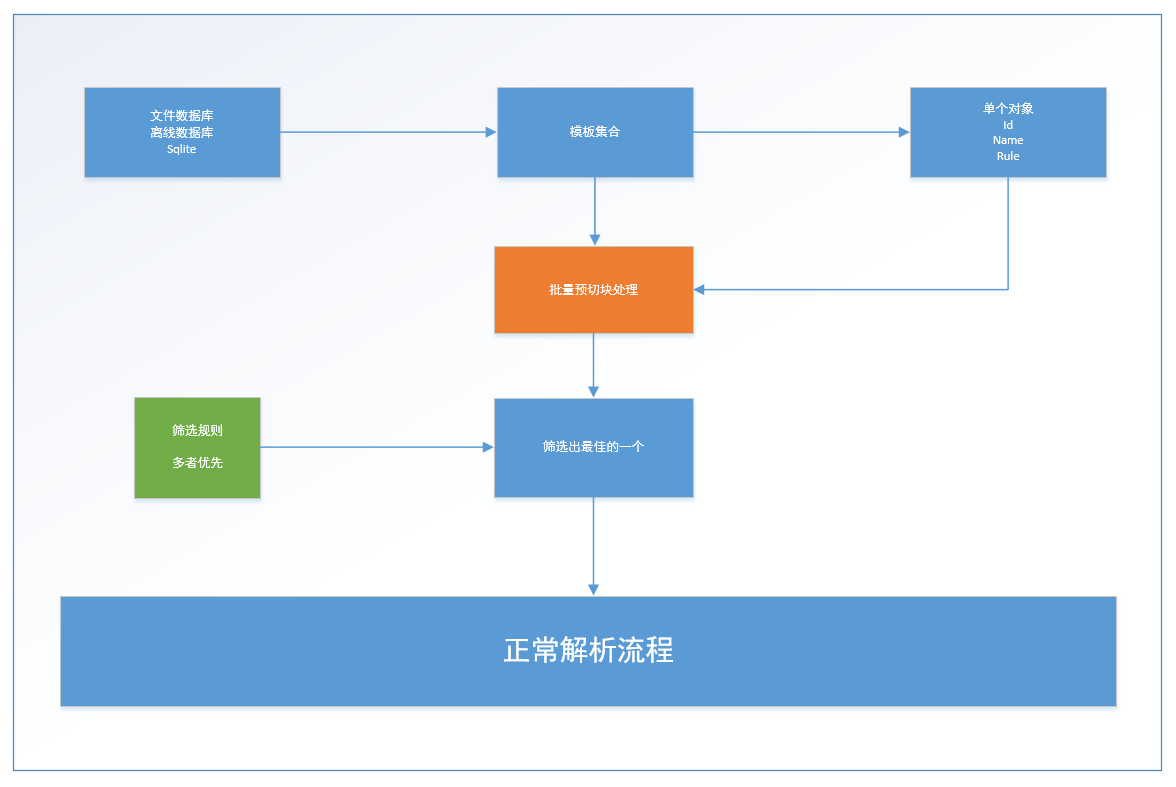
全自动匹配
其实,一开始我一直想避免模板,但是有人可能已经发现,在上面用到了模板,那就是切块。只是这个模板是文档标题,一般是旅游的各个模块,属于行业术语。虽然,有些术语不同地方叫法略有差异,但是配置门槛较低,也可以针对性的穷举。那么如果假设我们有一个穷举库,我们是不是可以达到自动匹配呢?当然可以。但是当时我这个项目没有分配数据库,而且我觉得操作数据库也极大的影响了性能,只做了一个简要的自动匹配。“模板”是用 SQLIT 录入和存储的,在项目启动的时候加载到缓存可以,避免频繁的数据库操作。由于没有评分系统,不能对各个模板进行优先级排序和特征记录,所以自动匹配只是粗暴的通过匹配到的数据数量高低来做判断优劣,不能自动运转优化。
后续
关于这个项目的思想主要就是这么一些,后续会尝试分享一些编码的经验。..