Word、PDF 解析项目(一)
前情提要
前一段时间做了文档解析相关的微服务,当然是和业务背景相关的业务数据提取,并不是对任何文档都能提取出正确的数据,而是针对旅行社的线路行程文档做的针对性解析服务。
应用场景
旅游行业供应商旅行社使用的 B 端软件有一个痛点,就是线路行程数据录入复杂耗时。由于不同旅行社线路行程文档风格几乎都不相同,即便是同一旅行社不同计调做出的文档风格也有所差异,即便是同一计调针对不同的类别的线路在不同的时期做出的文档也会有所不同。甚至有些旅行社是作为代理商,拿他们的产品做分销,又有更多无法控制的情况。如果按照常规做法,每一种风格的文档做一种文档模板(Word+PDF),每一种模板对应一种解析方式,这将是无法估计的工作量,特别在软件线路行程文档或业务数据若有变动的话,会有很大的迭代成本,相应的的维护代价和门槛也会变高。但是如果不做文档模板,如何保证准确性和稳定性呢,如何保证工作量可估量,如何保证后续的稳定迭代和有效的维护。
项目设计
项目启动初,需要给一个初步的项目设计,下面是项目内部的结构设计:
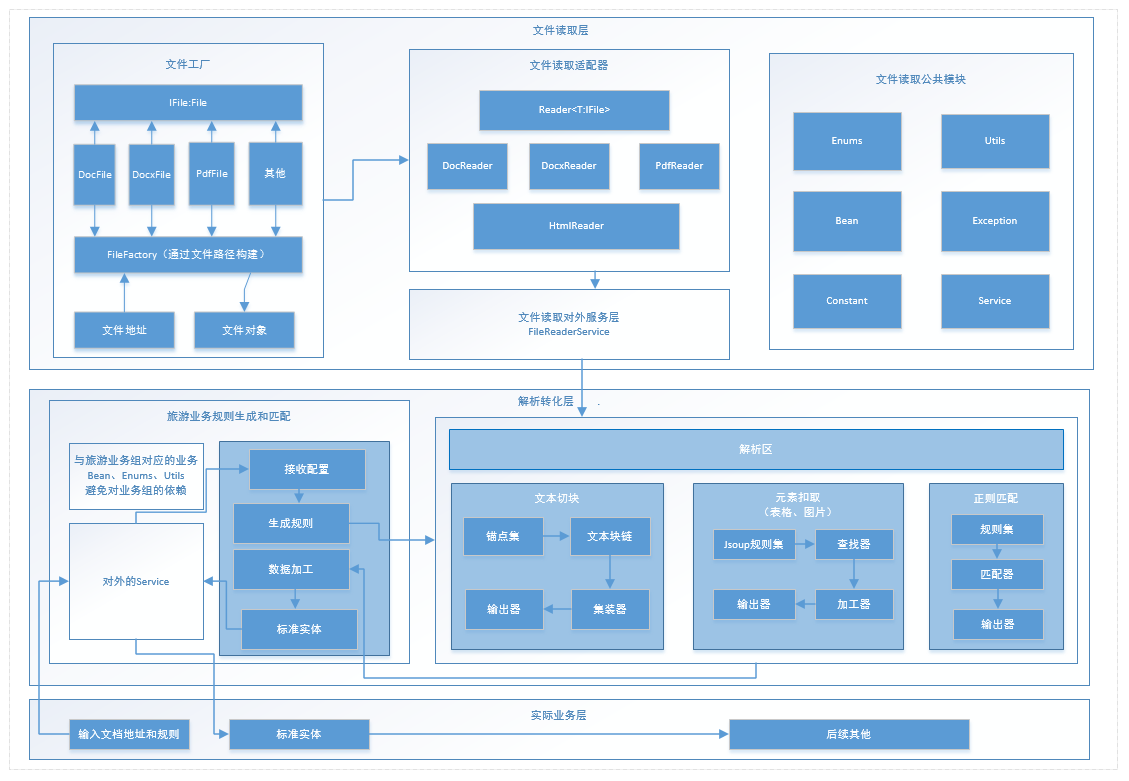
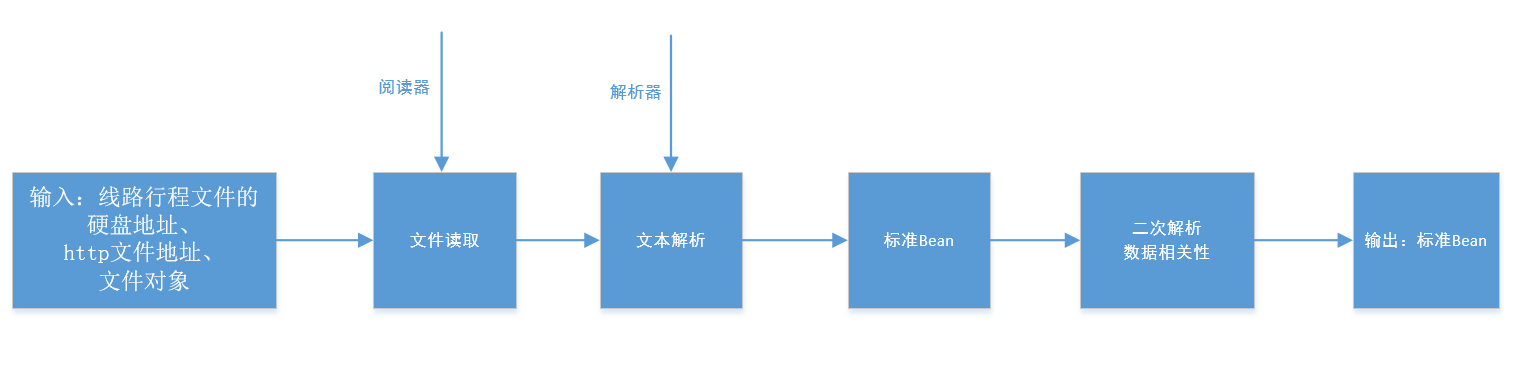
简化起来大概就是这个样子:
时间计划
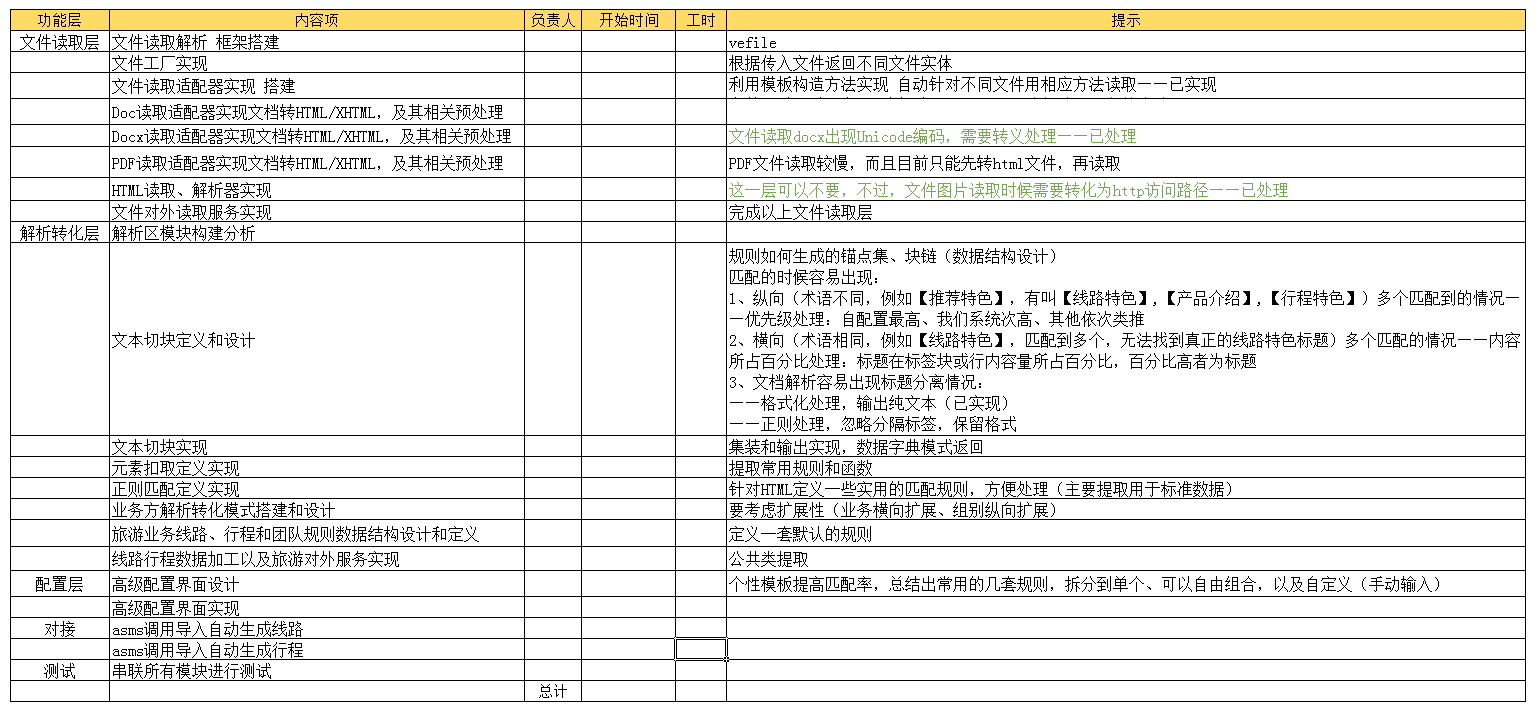
项目启动后,需要给一个简要的功能计划和时间的预估:
框架架构
- 精简 SpringMVC+Spring+Mybatis 框架配置;
- 支持 druid 控制台,监控请求、数据库和服务方法的性能;
- 支持页面和 Controller 交互,JSON 和对象的自动互相转换;
- 提供公共服务,也支持按业务线扩展开发;
- 支持 JUNIT4 测试和日志监控功能;
- 支持事务监控,自定义监控;
功能清单
- 文件读取解析 框架搭建
- 文件工厂实现
- 文件读取适配器实现 搭建
- DOC 读取适配器实现文档转 HTML/XHTML,及其相关预处理
- DOCX 读取适配器实现文档转 HTML/XHTML,及其相关预处理
- PDF 读取适配器实现文档转 HTML/XHTML,及其相关预处理
- HTML 读取、解析器实现
- 文件对外读取服务实现
- 解析区模块构建分析
- 文本切块定义和设计
- 文本切块实现
- 元素扣取定义实现
- 正则匹配定义实现
- 业务方解析转化模式搭建和设计
- 旅游业务线路、行程和团队规则数据结构设计和定义
- 线路行程数据加工以及旅游对外服务实现,接收文件或文件地址解析
- 高级配置界面设计
- 高级配置界面实现
- ASMS 对接服务导入 WORD 文档自动生成线路
- ASMS 对接服务导入 WORD 文档自自动生成行程
- 串联所有模块进行测试,实现线路、行程自动导入
后续
细节实现和项目过程中遇到的问题后续更新。..
邀请标记你的阅读体验😉 | →